Troubleshooting on MySQL RDS Aborted Connection Error with AWS LambdaDNX |
Recently, we noticed a ton of Errors in AWS CloudWatch Logs, the message like this:
2020-08-21T17:43:32.142855Z 8812 [Note] Aborted connection 8812 to db: 'dbname' user: 'db_user' host: 'x.x.x.x' (Got an error reading communication packets)
“Aborted connection" is a common MySQL communication error. The possible reasons are numerous includes:
- It takes more than connect_timeout seconds to obtain a connect packet.
- The client had been sleeping more than wait_timeout or interactive_timeout seconds without issuing any requests to the server.
- The max_allowed_packet variable value is too small or queries require more memory than you have allocated for mysqld.
- The client program did not call mysql_close() before exiting.
- The client program ended abruptly in the middle of a data transfer.
- A connection packet does not contain the right information.
- Any DNS related issues and the hosts are authenticated against their IP address instead of Hostnames.
Yes, it's a long list, unfortunately.
MySQL Tuning
We went thru the list, the first thing we tried was increasing those three variables:
- max_allowed_packet = 500M
- innodb_log_buffer_size = 32M
- innodb_log_file_size = 2047M
But they did not help, then we checked some timeout variables:
wait_timeout-this parameter refers to the number of seconds the server waits for activity on a non-interactive connection before closing it- Allowed value: 1-31536000
- The default value for MySQL 5.7: 28800
connect_timeout- this parameter the number of seconds that the server waits for a connect packet before responding with Bad handshake.- Allowed value: 2- 31536000
- The default value for MySQL 5.7:10
interactive_timeout- this parameter refers to the number of seconds the server waits for activity on an interactive connection before closing it.- Allowed value: 1-31536000
- The default value for MySQL 5.7: 28800
We have default values for all, so unlikely it is due to “The client had been sleeping more than wait_timeout or interactive_timeout seconds without issuing any requests to the server.”
Application Troubleshooting
It's enough for the MySQL tuning. We looked into the Application side. We use Lambda Serverless Apollo Server. The database connection is using KnexJS library. Our DB connection was something like this:
require('mysql');
const dbContext = require('knex')({
client: 'mysql',
connection: async () => {
return {
host: await getSecret(`${process.env.ENV}_DB_HOST`),
user: await getSecret(`${process.env.ENV}_DB_USER`),
password: await getSecret(`${process.env.ENV}_DB_PASSWORD`),
database: await getSecret(`${process.env.ENV}_DB_NAME`),
ssl: 'Amazon RDS'
};
},
pool: {
min: 2,
max: 10,
createTimeoutMillis: 30000,
acquireTimeoutMillis: 30000,
idleTimeoutMillis: 30000,
reapIntervalMillis: 1000,
createRetryIntervalMillis: 100
},
debug: false
});
export default dbContext;Updated (10/19/2020) We removed the pool settings propagateCreateError: true. Per Mikael (knex/tarn maintainer) -
the setting,
propagateCreateError,should never be touched.
There are many people having this issue on KnexJS GitHub issues channel (see the reference links below.) The key point here is that we are using serverless,
Lambda functions are stateless, so there is no way to share a connection pool between functions. - rusher
And our DB connection had pool setting as min:2 / max: 10. The good thing about connection pooling is that regarding wiki:
In software engineering, a connection pool is a cache of database connections maintained so that the connections can be reused when future requests to the database are required. Connection pools are used to enhance the performance of executing commands on a database.
The first expression for us was that since Lambda functions doe not share a connection pool, maintaining a connection pool becomes a waste here. Those connections sleep there do nothing, and they end up taking all the available connections. So as many people suggested, we changed the pool setting to be
pool: {
min: 1,
max: 1,
...Okay, after that, we saw some improvement. And we also did one thing:
const APIGatewayProxyHandler = (event, context, callback) => {
context.callbackWaitsForEmptyEventLoop = false;By specifying context.callbackWaitsForEmptyEventLoop = false, we allow a DB connection to be maintained in a global variable in the lambda's container resulting in a faster connection.
However, we noticed the performance issue after changing the connection pool to be min:1/max:1. Why? Did we just said, “Lambda functions doe not share a connection pool”? Let's be more clear, although Lambda functions do not share a connection pool, the queries in the same function do share a connection pool. For example, we have a GraphQL call, getCustomPages. When it's called, a DB connection is created, and then all queries in this call can share the connection pool, especially, those queries are written in an async way (i.e., with Promise) To demonstrate this, we can use MySQLWorkbench under Management/Client Connections. When the pool size is 1, we see only one connection created for one GraphQL call, but when the pool size is set to 2/10, we see more connections (about 10) are created for one call, and then we can see all queries are sharing those connections perfectly. We see page load time drops from ~10 seconds to a half-second by changing the connection pool from 1/1 to 2/10. That's because without sharing the pool, every query has to wait until another query finished before it can be executed. If a lambda function has thousands of queries in a loop, the big connection poll will truly boost the performance.
So for better performance, we should still use the default pool connection. But because AWS Lambda functions do not share the pool properly, the pool connection will be open for each Lambda function call and end up using all of the available MySQL connections.
After looking into tarn.js, the library KnexJS used to manage the connection pool, we found out that the setting idleTimeoutMillis controls how many mill seconds before the free resources are destroyed. For example, if we set it to 30000, ie. 30 seconds, then the idle connections will be destroyed after 30 seconds. However, it will not destroy all sleeping connections, but keep the minimum number of connections set in the pool configuration. Since we cannot reuse the pool connection in the next Lambda function call, why not set the minimum to 0?
Brilliant! The final solution we have is:
- Use the pool settings as: (Updated: 8/26/2020 - since the connections are not shared by next Lambda function call, we could set idelTiemoutMillis to be much shorter, and we changed it to 1000 from 30000.)
pool: {
min: 0,
max: 10,
createTimeoutMillis: 30000,
acquireTimeoutMillis: 30000,
idleTimeoutMillis: 1000, //changed it from 30000 to 1000
reapIntervalMillis: 1000,
createRetryIntervalMillis: 100,
propagateCreateError: true
},- Set
context.callbackWaitsForEmptyEventLoopto befalse(Note: the DB connection outside of Lambda handler function)
const APIGatewayProxyHandler = (event, context, callback) => {
context.callbackWaitsForEmptyEventLoop = false;The Ultimate Solution
As we repeated many times above, the bottleneck of the AWS Lambda functions is that they don't share the resource. To better understand this, please check the following images:
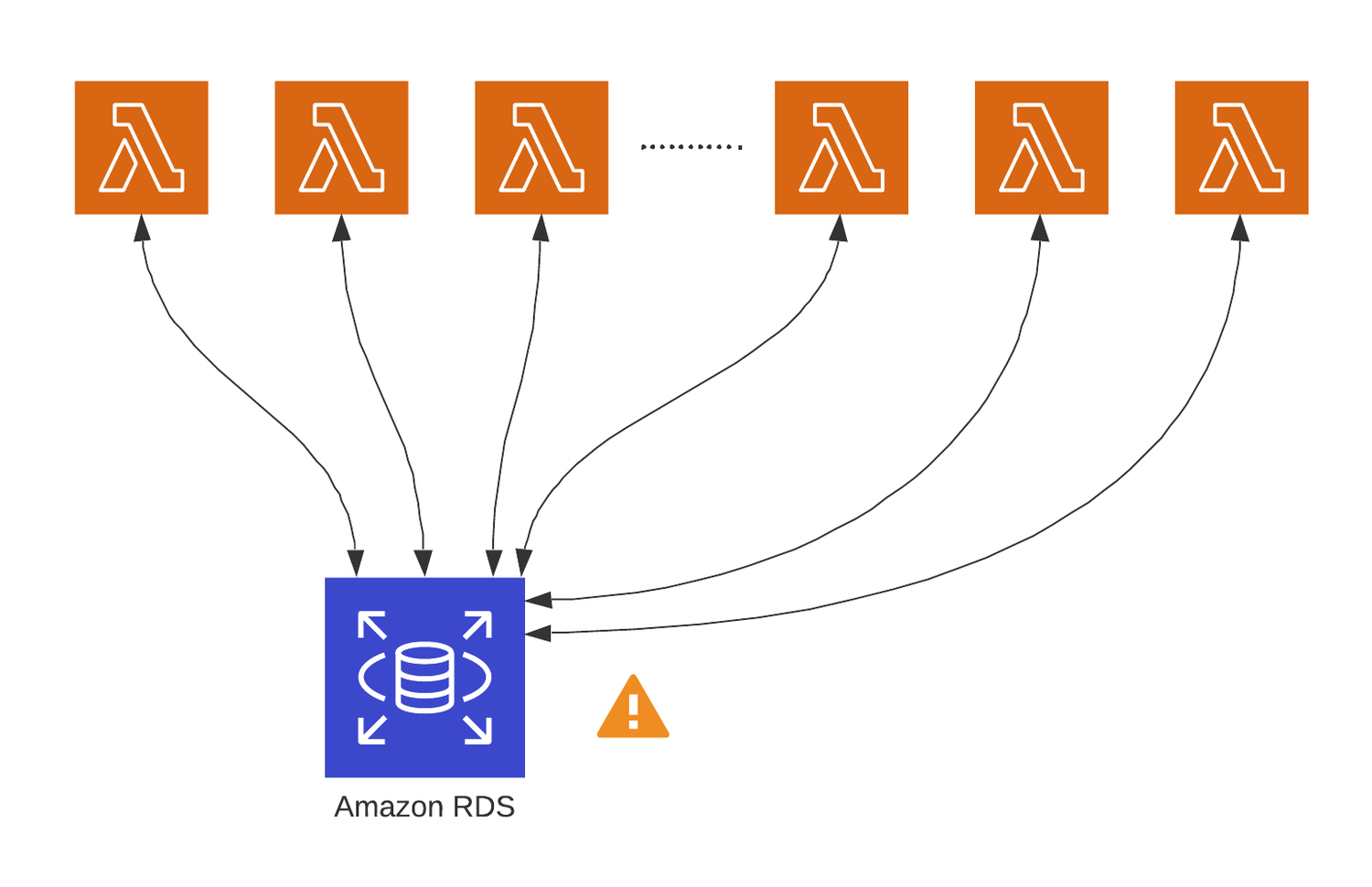
Since each Lambda function is an individual process, it has to establish its connection to the DB instance. This design becomes very resource-intensive.
Luckily, Amazon launched the preview of Amazon RDS Proxy in December 2019 and then made it generally available for both Mysql and PostgreSQL engines in Jun 2020, which address this issue. We call it “the Ultimate Solution” here. :-)
Amazon RDS Proxy allows applications to pool and share connections established with the database, improving database efficiency, application scalability, and security. RDS Proxy reduces client recovery time after failover by up to 79% for Amazon Aurora MySQL and by up to 32% for Amazon RDS for MySQL. Also, its authentication and access can be managed through integration with AWS Secrets Manager and AWS Identity and Access Management (IAM).
Again, we borrow a beautiful diagram from Thundra:
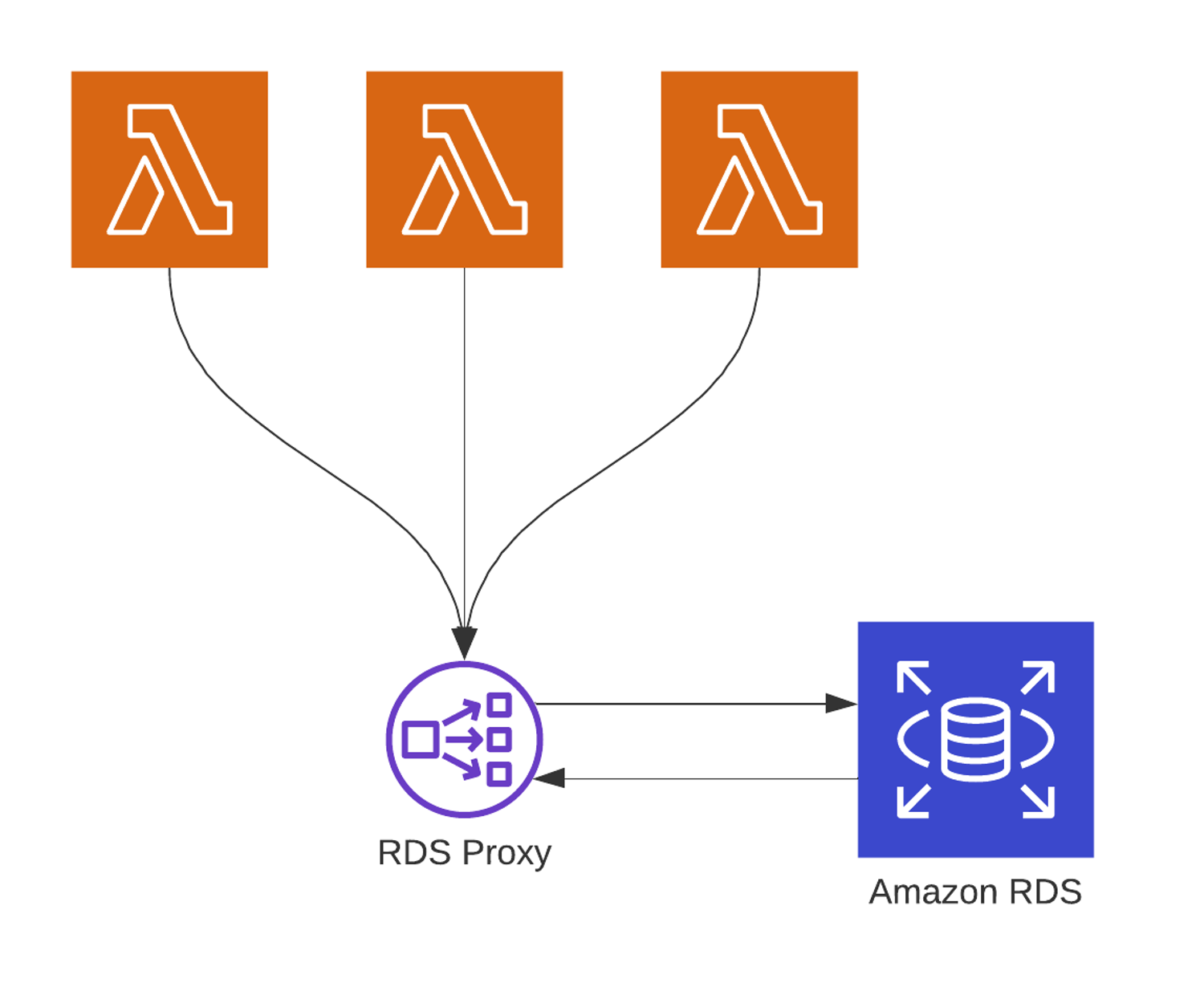
Please follow the links to see how to set up Amazon RDS Proxy if you are interested. We are about the end of this long long post. Thank you for reading.
Updated (08/27/2020): We added AWS RDS Proxy.
References:
- https://github.com/knex/knex/issues/1875 (How do I use Knex with AWS Lambda
- https://github.com/vincit/tarn.js (Another Resource Pool)
- https://blog.thundra.io/can-lambda-and-rds-play-nicely-together (Play Lambda and RDS Nicely Together)
- https://aws.amazon.com/blogs/aws/amazon-rds-proxy-now-generally-available/ (AWS RDS Proxy)